Dominic Cronin's weblog
Tridion MVP retreat 2017
It's become a regular feature of my year: the Tridion MVP retreat. This year I was fortunate enough to be invited again, and as usual it lived up to my expectations. So let me start by saying thank you to SDL for the invitation and hospitality throughout, and particularly to Carla and her team in Portugal for making it all a reality. Thanks also to the Tridion community: the award is firmly rooted there, and none of us would be there but for the inspiration that comes from helping each other and being helped the whole year through.
Others have blogged about the technical wonders we produced at the retreat: web frameworks, diagnostic tools, scripting libraries, Tridion extensions and other kinds of voodoo. It always amazes me how much technical goodness comes out of the retreat, and this year was no exception. OK - so often enough, things don't get finished while we're still in Portugal, but they usually get finished. The great thing is getting all these initiatives started. I worked in a team with Jonathan Williams, Rick Pannekoek, and Siawash Sibani, trying to demystify some of the magic underlying the Experience Manager. We tried to figure out what the challenging questions are for implementers, and to get some solid answers for those. (Speaking of demystifying - special thanks to Rick for the extra time he spent helping me to get a much better understanding of DXA.)
So what's so great about getting to be an MVP and going to the retreat? To be honest, it's hard to put your finger on any one thing. I could mention the great hospitality, and the fact that somehow I managed to put on two and a half kilograms in the four days of the retreat. What can you do? They keep taking you to great restaurants. It's become our tradition that every night, not only do we talk into the wee small hours, but we also make music. I could talk about the cultural visits (like to the catholic shrine at Fatima) or the spectacular wonders of nature (like the boat trip at Nazaré - famous for the highest wave ever surfed).
Somehow, all of these things are great, and I enjoyed them all to the full, but still none of them are the defining feature of the retreat. Someone once said that if you're the smartest person in the room, you're in the wrong room. One thing is certain about the MVP retreat, and that is that you aren't going to be the smartest person in the room. Don't get me wrong, MVPs aren't selected for being smart, but somehow, they manage to be an inspiring group. The funny thing is, that talking to the guys - every single one of us felt that we were privileged to be surrounded by a bunch of people that would challenge us and bring us new insights. OK - maybe we all suffer from the impostor syndrome, but it's also true that each of us brings something different to the party.
One thing I've noticed at previous retreats, and this time it was no different, is the way that the conversation can run from general chat about the state of the universe, to stupid jokes, to shared experiences from our working lives, and then without dropping a beat, you'll suddenly see bizarrely deep technical discussions break out like wildfire. In this company, all these things have equal value, and that is a special thing.
For this reason, the image I've chosen to accompany this blog post is not of the surf at Nazare or the castle at Ourém but of a moment late at night, when the subject turned to JavaScript, and I suddenly realised that our resident web guru Frank Taylor had embarked on enlightening a small group about the joys of type coercion in that language. Don't ask me why, but this kind of thing breaks out spontaneously. If it wasn't Javascript it would have been content deployment archtecture or something else. You can't predict what's going to come up. I hope I'm there to see what it will be next time.
deployer-conf.xml barfs on the BOM
Today I was working on some scripts to provision, among other things, the SDL Web deployer service. It should have been straightforward enough, I thought. Just copy the relevant directory and fix up a couple of configuration files. Well I got that far, at least, but my deployer service wouldn't start. When I looked in the logs and found this:
2017-09-16 19:20:21,907 ERROR NonLegacyConfigConditional - The operation could not be performed.
com.sdl.delivery.configuration.ConfigurationException: Could not load legacy configuration
at com.sdl.delivery.deployer.configuration.DeployerConfigurationLoader.configure(DeployerConfigurationLoader.java:136)
at com.sdl.delivery.deployer.configuration.folder.NonLegacyConfigConditional.matches(NonLegacyConfigConditional.java:25)
I thought it was going to be a right head-scratcher. Fortunately, a little further down there was something a little more clue-bestowing:
Caused by: org.xml.sax.SAXParseException: Content is not allowed in prolog.
at org.apache.xerces.parsers.DOMParser.parse(Unknown Source)
at org.apache.xerces.jaxp.DocumentBuilderImpl.parse(Unknown Source)
at com.tridion.configuration.XMLConfigurationReader.readConfiguration(XMLConfigurationReader.java:124)
So it was about the XML. It seems that Xerxes thought I had content in my prolog. Great! At least, despite its protestations about a legacy configuration, there was a good clear message pointing to my "deployer-conf.xml". So I opened it up, thinking maybe my script had mangled something, but it all looked great. Then some subliminal, ancestral memory made me think of the Byte Order Mark. (OK, OK, it was Google, but honestly... the ancestors were there talking to me.)
I opened up the deployer-conf.xml again, this time in a byte editor, and there it was, as large as life:
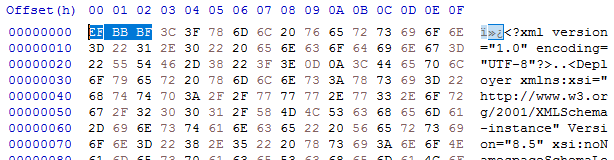
Three extra bytes that Xerxes thought had no business being there: the Byte Order Mark, or BOM. (I had to check that. I'm more used to a two-byte BOM, but for UTF-8 it's three. And yes - do follow this link for a more in-depth read, especially if you don't know what a BOM is for. All will be revealed.)
What you'll also find if you follow that link is that Xerxes is perfectly entitled to think that, as it's a "non-normative" part of the standard. Great eh?
Anyway - so how did the BOM get there, and what was the solution?
My provisioning scripts are written in Windows PowerShell, and I'd chosen to use PowerShell's "native" XML processing, which amounts to System.Xml.XmlDocument. In previous versions of these scripts, I'd used XLinq, but it's not really a good fit with PowerShell as you can't really use XPath without extension methods. So I gave up XLinq's ease of parsing fragments for a return to XmlDocument. To be honest, I wouldn't be surprised if the BOM problem also happens with XLinq: after all, it's Xerxes that's being fussy - you could argue Microsoft is playing "by the book".
So what I was doing was this.
$config = [xml](gc $deployerConfig)
Obviously, $deployerConfig refers to the configuration file, and I'm using Powershell's Get-Content cmdlet to read the file from disk. The [xml] cast automatically loads it into an XmlDocument, represented by the $config variable. I then do various manipulations in the XmlDocument, and eventually I want to write it back to disk. The obvious thing to do is just use the Save() method to write it back to the same location, like this:
$config.Save($deployerConfig)
Unfortunately, this gives us the unwanted BOM, so instead we have to explicitly control the encoding, like this:
$encoding = new-object System.Text.UTF8Encoding $false
$writer = new-object System.IO.StreamWriter($deployerConfig,$false,$encoding) $config.Save($writer) $writer.Close()
As you can see, we're still using Save(), but this time with the overload that writes to a stream, and also allows us to pass in an encoding. This seems to work fine, and Xerces doesn't cough it's lunch up when you try to start the deployer.
I think it will be increasingly common for people to script their setups. SDL's own "quickinstall" doesn't use an XML parser at all, but simply does string replacements based on its own, presumably hand-made, copies of the configuration files. Still - one of the obvious benefits of having XML configuration files is that you can use XML processing tools to manipulate them, so I hope future versions of the content delivery microservices will be more robust in this respect. Until then, here's the workaround. As usual - any feedback or alternative approaches are welcome.
Connecting to Microsoft SQL Server Developer from Tridion Content Delivery
I've recently been setting up a development image for SDL Web 8.5, and as it's only for use on my development rig, it's fair game to use Microsoft SQL Server Developer edition. It's not supported by SDL, but it's close enough to make it a reasonable risk for my purposes. I got the databases set up and the content manager installed OK, so I moved on to the content delivery stack.
First I hacked together a database test script to make sure I had all the logins correct etc. I've done it this way for years, and you may have seen my blog about it quite a long time ago. Everything seemed fine.
I'd started with the Discovery service, and I'd configured the cd_storage_conf.xml with the relevant database settings I'd just tested. How hard could it be? Except that it didn't work. I got messages in the logs telling me to check my firewall. Doh! Off I went and opened up the firewall ports for my microservices (which I'd forgotten to do) and also 1433 for MSSQL. Still no joy.
Somewhere along the way I'd also disabled loopback checking and double-checked a bunch of other things that can cause trouble. No joy.
I went back to my database test script a few times. It uses a System.Data.SqlClient.SqlConnection to execute a simple command. The connection string specifies '(local)' as the server. I'd had trouble with using '(local)' in the cd_storage_conf.xml in a previous version of Tridion, so I had specified 'localhost' instead, and then when that didn't work, a different name that mapped to the same interface. Still nothing.
The troubling thing was that the test script worked fine. Why was that, when Tridion's java stack had trouble doing the same thing? I should have cottoned on to this way earlier, but eventually I started checking to see if there was actually anything listening on 1433. No there wasn't. Well that helped. And then I started poking around in the network configuration of SQL Server. Sure enough: TCP/IP wasn't enabled. I'm still not sure if this is a Developer edition thing. I seem to recall having come across it before. I'm not the only one. Now that I know the answer, finding a suitable Stack Overflow answer is easy! Maybe I'd had trouble with SQLEXPRESS.
Anyway, at least that explained why my test script worked OK. The SqlConnection client sees '(local)' and is then able to attempt a named pipes or shared memory connection as well as TCP/IP. The java client, on the other hand, doesn't have this repertoire of options and if TCP/IP fails, it's over.
Anyway - now it's fixed. Just time for a quick Note To Self, and on with the rest of my system.
Character encodings and the SDL Web 8 deployer - a journey through double-encoded UTF-8
I spent some time yesterday and today working with a colleague to resolve an encoding issue in our new SDL Web 8.5 publishing systems. It's a migration from an older Tridion implementation that manages several portals, including a very old one in which the default encoding is ISO-8859-1.
For various historical reasons, even for the portals which use UTF-8, the code page has always been set explicitly in the template, using something like setCodePage(1252) or setCodePage(65001) in the vbScript of the page template. (The pedantic among you may have noted that code page 1252 is not the same as ISO-8859-1, and even though some of the characters we were having trouble with were, indeed, quotation marks in the control codes range, I'm going to let that particular distinction slide for the purpose of this blog post. An exercise for the student, as they used to say... )
So most of the sites are in UTF-8, and had setCodePage(65001) in the templates. These worked fine with the out-of-the-box installation of the deployer service. Even the gnarliest of funky characters were transmitted faithfully from end to end. The trouble was with the old site that had code page 1252. On this site, any vaguely interesting characters were incorrectly displayed. OK - this might not have been too much of a surprise.
In SDL Web 8, publication targets have been replaced as part of the move to the new "Topology Manager"-based architecture. So where we'd previously had the option to specify a default encoding on a publication target, now the matching configuration had moved to the deployer. (Or at least to the CD environment - strictly it's a Deployer Capability which is exposed by the Discovery service.) The general assumption seems to be that all sites sharing a deployer will also share an encoding. It's not actually so daft an idea. Most sites these days just use UTF-8 and have done with it. Even if you really, really, really want to have sites with different encodings, well you could always run up another environment, couldn't you? Microservices FTW!
By the time we'd come to this understanding, my colleague had already spent quite some time experimenting with different settings. We'd ended up being able to show that we could get one or the other working, but not both at the same time. We didn't want to set up extra CD environments throughout the DTAP, so the obvious approach was to fix up the old site to use UTF-8. What's not to like? In the beginning I hadn't realised that the old site also used setCodePage(1252) - it was buried pretty deep. So my first approach was simply to get into the templating and fix up the JSP page directive so that we were sending the right contentType header, and specifying pageEncoding="UTF-8". However... no joy.. we still had bad characters, so I then dug deep enough to find the relevant routine. I duly changed it to setCodePage(65001) and smugly headed off to get a cup of coffee while it all published.
By the time we had some published output to look at, we realised, that the "interesting" characters were now double-encoded UTF-8. (You can usually tell this just by looking. You tend to see pairs of characters, the first of which is often an accented A, like å or Ã.) So what was happening?
TL;DR
- It turns out that even in Web 8, the renderer is capable of creating transport packages in a variety of encodings. If you specify 1252 programatically in the template, the page in the zip file will be encoded with that encoding. Likewise for 65001/UTF-8. Not only will the renderer use the specified encoding, but it will tell the truth about this when it writes the <codepage> element in the pages.xml file.
- With neither a publication target nor a programatically specified code page, UTF-8 will be used in the transport package.
- No further encoding will take place until the package reaches the deployer and is unzipped.
- When reading the newly received page, the deployer will use the current default encoding of its JVM. If you don't specify this, the default will be the default encoding of your operating system. On Windows, usually code page 1252, and on Linux usually UTF-8. (Obviously, this means it's ignoring the information about encoding that's embedded in the deployment package. You could argue that this might be a bug.)
- The installation scripts for the deployer configure the service to pass various arguments to the JVM on startup, including "-Dfile.encoding=UTF-8". This matches the assumption that you have no publication target and the incoming encoding is therefore UTF-8.
- In our case, we left the Deployer Capability setting at UTF-8.
The reason we had seen double-encoded UTF-8 was that after the various experimentation, we no longer had the -Dfile.encoding=UTF-8 parameter controlling the JVM startup. Without this, when we were successfully sending UTF-8 in the deployment package, it was being read in as cp1252, and then dutifully re-encoded to the encoding specified in the Deployer Capability registration: UTF-8.
Without this setting, at one point we had also successfully used cp1252, with the output rendered correctly as UTF-8.
Once we'd figured it all out, we got the whole thing working with all sites running UTF-8. This is almost certainly better than having to worry about a variety of different settings in your infrastructure.
As with any investigation of encodings, a byte-editor is your friend, and plenty of patience to look carefully at what you're seeing. In the end, you'll get there!
Decoding webdav URLs (or how to avoid going cross-eyed reading your error messages)
I was doing some Content Porting the other day. When moving code up the DTAP street the general practice is to switch off dependency management and, well, manage the dependencies yourself. This is great for a surgical software release, where you know exactly what's in the package and can be sure that you aren't unintentionally releasing something you hadn't planned to, but....
Yeah - there's always a but. In this case, you have to make sure that all the items your exported items depend on are present, either in the export or in the target system. Sometimes you miss one, and during the import you get a nice error message saying which item is missing. Unfortunately, the location of the item is given as a WebDAV URL. If the item in question has lots of spaces, quote marks, or other special characters in it, by the time you get to read the URL in all its escaped glory, it can be a complete alphabet soup.
So there I was, squinting at some horrible URL and mentally parsing out the escape sequences to figure out what I was looking at.. when it dawned on me. Decoding encoded URLs is not work for humans - we have computers for that. So I fired up my trusty Powershell, thinking "hey, I have the awesome power of the .NET framework at my disposal". As it turns out, the HttpUtility libraries that most devs are familiar with is probably not there in your ordinary desktop OS, but System.Net.WebUtility is. So if you've copied a webdav url into your paste buffer, you can open the shell, type in
[net.webutility]::Ur
From here on tab completion will fill in the rest of UrlDecode, and with one or two more keystrokes and a right-mouse-click you have something like this:
[net.webutility]::UrlDecode("/webdav/Some%20Publication/This%20%26%20that/More%20%22stuff%22%20to%20read/a%20soup%C3%A7on%20of%20something")
and then hitting enter gets you this:
/webdav/Some Publication/This & that/More "stuff" to read/a soupçon of something
which is much more readable.
Of course, if even that is too much typing for you, you can stick something like this in your profile:
function decode ($subject) {
[net.webutility]::UrlDecode($subject)
}
Of course, none of this is strictly necessary - you can always stare at the WebDAV URLs and decipher them as an exercise in mental agility, but some days you just want the easy life.
Websphere and Xalan fun for SDL Web 8
Of the small number of people who follow this blog, an unreasonably large proportion will be familiar with SDL Web 8, and the promise it holds for freedom from classpath hell. The new service-based architecture is a huge step forward, but we aren't out of the woods yet. I'm currently busy with an upgrade project where we're taking an interesting mix of web applications from SDL Tridion 2011 to SDL Web 8.
Web 8's much-vaunted REST-ful microservice approach was initially communicated as pretty much a drop-in replacement for the existing Content Delivery APIs. In practice, it turned out that the focus on backwards compatibility wasn't as clear as it might have been, and if you use JSPPage when invoking dynamic component presentations from a JSP page, you are out of luck, because this class doesn't have an implementation in the REST-ful facade. This is annoying, as I can't see any reason why it couldn't or shouldn't be made to work. The missing support is a "known issue", however I'm told there's not much appetite for fixing it. After all, goes the argument, we can use the in-process API, which does have JSPPage, so that's a workaround isn't it? Except that then we don't get the benefit of the dependency-free service architecture, and that, as I shall explain, is no small thing.
With the in-process API, of course, the idea is that all the necessary jars to do Tridion content delivery things have to be on your classpath. The general idea is simple enough, but in practice, we have to deal with the fact that there are several class-loaders arranged in a hierarchy, and each of these has their own classpath, although it's not always called that. At the top you've got the class loaders that belong to java itself. This means the boot classloader that loads the nuts and bolts of java itself, and also the one that works from the java CLASSPATH variable plus one for java extensions. And then lower down you have Websphere's own extensions classloader, some magic called the OSGi class loader gateway, and then the application's class loader and one for the module. Yes I know - it sounds pretty insane, but I didn't make it up. Have a look over here if you don't believe me!
So what kind of trouble did we get into, and how did we get out of it? Well we had all the Web 8 jars in a directory, and we'd deployed our application and set things up so the jars would be on the classpath. Keeping the jars outside the application has been the customer's preferred way of doing things for some years, and it's worked well, so our initial expectation was that things should "just work", but once we started testing, we started to see exceptions like:
[java.lang.ClassCastException: org.apache.xml.dtm.ref.DTMManagerDefault incompatible
with org.apache.xml.dtm.DTMManager
This is a bit of a weird one, because if you look up the sources, org.apache.xml.dtm.ref.DTMManagerDefault and org.apache.xml.dtm.DTMManager are actually defined in the same jar. How could they possibly be incompatible? Well as it turns out, it's possible for java to load two incompatible versions of the same jar simultaneously, from different jars.
If you look it up, this problem is about the Xerxes library, and it's associated serialiser jar. I think this comes about because Websphere uses Xerxes itself, (as do several other application servers) and because Tridion's own Content Delivery installation has these as third-party jars, any difference in the required versions will be problematic. Of course, it could happen with other libraries, but in practice, it's Xerces. (OK - so we also had similar issues with another application that uses JSTL.)
But let's start with "parent first" and "parent last". When working with the hierarchy of classloaders, the default method of loading a class is parent first. What this means is that when the module classloader needs to load a class, it first checks to see if its parent (the application classloader) can load the class. The application classloader then asks its parent, and so on all the way up. I've visualised this in the left hand diagram with the arrows going down, because in practice, what this means is that classes are made available from the top down. If the java classloaders have the class, that's what will be used throughout.
Parent last is the opposite arrangement. If the module classloader can find the class in its classpath, it loads it itself and doesn't trouble the parents with it. This effectively means that the lower the classloader, the higher priority its jars have, and hence the direction of the arrows in my right-hand diagram.


So to get rid of the ClassCastException, we flipped the configuration from Parent First to Parent Last. This works. It's what SDL recommend that you should do if you encounter these exceptions in your environment. But...
Well it turned out that our problems weren't over. Instead of a ClassCastException, now we had a ClassNotFoundException. I can't post it here, because all this happened a while ago and I'm writing this up later, but as I said earlier, it's all about Xerces. The problem in this case is that if a class is loaded by a classloader, it can't call a class that's loaded by a classloader that's lower in the hierarchy. Parent last leaves you rather more sensitive to this kind of problem, because you're deliberately loading classes lower down that might also be available further up the tree, and also might be expected by classes further up. In any case, even though the class is available, it can't be loaded, and you get a ClassNotFoundException.
In our case, we were able to solve the problem by moving the xalan and serialiser jars to Websphere's ws.ext directory, where they would be loaded by the Websphere Extensions classloader.
All this is a bit like the "dll hell" that we used to waste days on on Windows systems before the .NET framework came along. Sooner or later, the answer always ended up being that you needed to know far more than you wanted to about the nuts and bolts of how it all worked, and the various possible locations that Windows would look for a dll. "Classloader hell" is not much different. I've been able to avoid it for a long time just by breezily saying - "Oh yes - that's a Java problem". These days, I seem to be more engaged with Java than I used to be, so having to figure out classloader hell is probably fair game.
It's been a while since I linked to Joel Spolsky's classic: "The law of leaky abstractions", but this seems like a reasonable moment to do so. Joel's piece probably makes for far more entertaining reading than either this, or this, (both of which are pretty good) or any of the other detailed coverage that Google will turn up for you on the complexities of classloaders. My own description here has been deliberately only a sketch to give the big picture. I've skated over many details, missed others out entirely, and probably got a few things wrong (in which case, comments are welcome). My point is that in any given environment, there's a good chance you'll have to solve this kind of thing. It's frustrating, and it costs time that you probably feel like you don't have, but once you engage with the detail, you will find a solution. I'm not saying the solution outlined here is the best one. There may be other ways to get it working, and some of them may well be better.
To finish on a rather more upbeat note, we should all be happy to be moving slowly but surely towards the new architecture. Having to deal with these issues is actually a very welcome reminder of why we're investing in new architectures in the first place. The difficulty lies in the fact that you can't necessarily have a rebuild of all your legacy systems in the scope of an upgrade project, so we live with some things that aren't perfect, but we are moving in the right direction. Next time will be better!
Revisiting validateXml
Some time back in 2009 I blogged about validating Tridion's content delivery configuration files. It was a good idea then, and it's remained a good idea ever since. These days, we're dealing with SDL Web 8 and with the new micro-services architecture, you've got a lot of configuration files to get right. (On my fairly unambitious test system, running staging and live together, I just counted almost 80 configuration files.) Fortunately these seem to be reliably supported with schema files that are simply in each of the microservice folders that you copy during an installation.
Back when I first wrote the ValidateXmlFile powershell function, I'd left it rather unfinished. It was good enough to let me do some validations and detect problems, but it had a significant flaw, in that if a schema file was not present at the location indicated by the noNamespaceSchemaLocation attribute, it would simply not bother with validation. Considering that we're using an XmlReader to do the validation, this is a pretty reasonable design decision - after all the main purpose is to read in the XML, and validation is perhaps a bit of a side-effect. Fair enough, but it's a nasty hole in our defences, so now that I'm revisiting the technique, I've beefed up the script a bit so that it checks that the location is present and that there's a file in the location.
I've also made sure that the script does some pushd/popd to make sure that everything is nicely lined up when the location is relative to the file (which it generally is).
Here's the updated script:
function ValidateXmlFile {
param ([string]$xmlFile = $(read-host "Please specify the path to the Xml file"))
$xmlFile = resolve-path $xmlFile
"==============================================================="
"Validating $xmlFile using the schemas locations specified in it"
"==============================================================="
# The validating reader silently fails to catch any problems if the schema locations aren't set up properly
# So attempt to get to the right place....
pushd (Split-Path $xmlFile)
try {
$ns = @{xsi='http://www.w3.org/2001/XMLSchema-instance'}
# of course, if it's not well formed, it will barf here. Then we've also found a problem
# use * in the XPath because not all files begin with Configuration any more. We'll still
# assume the location is on the root element
$locationAttr = Select-Xml -Path $xmlFile -Namespace $ns -XPath */@xsi:noNamespaceSchemaLocation
if ($locationAttr -eq $null) {throw "Can't find schema location attribute. This ain't gonna work"}
$schemaLocation = resolve-path $locationAttr.Path
if ($schemaLocation -eq $null)
{
throw "Can't find schema at location specified in Xml file. Bailing"
}
$settings = new-object System.Xml.XmlReaderSettings
$settings.ValidationType = [System.Xml.ValidationType]::Schema
$settings.ValidationFlags = $settings.ValidationFlags `
-bor [System.Xml.Schema.XmlSchemaValidationFlags]::ProcessSchemaLocation
$handler = [System.Xml.Schema.ValidationEventHandler] {
$args = $_ # entering new block so copy $_
switch ($args.Severity) {
Error {
# Exception is an XmlSchemaException
Write-Host "ERROR: line $($args.Exception.LineNumber)" -nonewline
Write-Host " position $($args.Exception.LinePosition)"
Write-Host $args.Message
break
}
Warning {
# So far, everything that has caused the handler to fire, has caused an Error...
# So this /might/ be unreachable
Write-Host "Warning:: " + $args.Message
break
}
}
}
$settings.add_ValidationEventHandler($handler)
$reader = [System.Xml.XmlReader]::Create($xmlfile, $settings)
while($reader.Read()){}
$reader.Close()
}
catch {
throw
}
finally {
popd
}
}
Of course, what you really want is to be able to verify all your configurations in one go. Once the script is in your powershell $profile, you can put together some fairly simple command-line-fu to take care of that. I have all my microservices in one directory, which I guess is a pretty common pattern, so all I had to do was CD over there and execute the following:
gci -r -file -include *conf.xml | % {ValidateXmlFile $_}
By running this, I've also picked a couple of things that might be false positives. That aside, this is a real time saver if you're trying to solve issues. There's nothing like being able to eliminate a lot of the stupid typos from consideration all in one go.
Upgrading SDL Web Microservices - don't copy new over old
I've just broken my Tridion system. I had a perfectly good SDL Web 8.1.1 installation, and I've broken it upgrading to 8.5. This is really annoying. I'm gritting my teeth as I type this, and trying not to actively froth at the mouth. It's annoying for two reasons:
- The documentation told me to
- I got burned exactly the same way going form 8.1 to 8.1.1 and I don't seem to have learned my lesson.
So what exactly am I ranting about? Let me explain.
Take the discovery service as an example, but the same thing applies to the other services. Look at the documentation for Upgrading the Discovery Service. Check out the highlighted line below:

Doing this goes against the grain for anyone with experience of setting up servers. Copying a clean "known good" situation over a possibly dirty implementation and expecting it to work is asking for trouble. I'd never have written these instructions myself. What on earth was I thinking when I blindly followed them?
The service directory that you're attempting to overwrite contains a lib directory full of jars, and a services directory containing yet two more directories of jars. What you want to do is replace the jars with their new versions. This would be fine if all the jars had the same name as before, and there weren't any that shouldn't be there any more. As it is, the file names include their version numbers, so you end up with both versions of everything, like this:
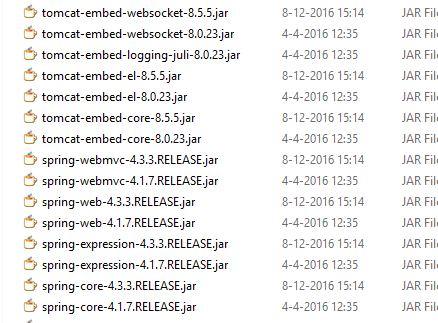
This results in messages like "Class path contains multiple SLF4J bindings" and ensures that your services don't start. The solution is simple enough. Go to the various directories, and make sure that they contain only the jars from the 8.5 release.
Fortunately, I'm still feeling very positive about the folks at SDL in the wake of having received the MVP award again. I suppose I'll forgive them.... once I finish cleaning up the rest of my services.
Update: After posting this fairly late last night, it's now not even lunch time the following day, and I've already been informed that SDL have seen this, and are already taking action to update the documentation. That's pretty good going. Thanks
Checking your DXA/DD4T JSON in the SDL Web broker database
Over at the Indivirtual blog, I've posted about a diagnostic technique for use with the SDL Web broker database.
https://blog.indivirtual.nl/checking-dxadd4t-json-sdl-web-broker-database/
Enjoy!
Testing the SDL Web 8 micro-services
Over at blog.indivirtual,nl I've just blogged about testing the SDL Web 8 microservices.