Dominic Cronin's weblog
Preparing HTML data for use in a Tridion Rich Text Format area
I recently had to create some Tridion components from code via the core service. The incoming data was in the form of HTML, and not XML in the XHTML namespace, which is what is required for a Tridion RTF area. I'd also had to do some preparatory clean-up of the data, and by the time I wanted to fix up the namespaces, I already had the input data in an XLinq XElement.
These days, if I'm processing XML in .NET, I'm quite likely to use XLinq. It's taken me a while to get comfortable with some of its idioms. The technique I ended up using is similar to the classic approach we typically adopt in XSLT, starting with an identity transform and making a couple of minor tweaks to the data as it goes through.
So, mostly by way of a "note to self", here's how it looks in XLinq. All you need to do is pass in your XElement containing your XHTML, and it will rip through all the elements and put them in the XHTML namespace, leaving all the attributes and other nodes untouched.
public XNode PutHtmlElementsInXhtmlNamespace(XNode input){
XNamespace xhtmlNs = "http://www.w3.org/1999/xhtml";
var element = input as XElement;
if (element != null)
{
XName name = xhtmlNs + element.Name.LocalName;
return new XElement(name,element.Attributes(),
element.Nodes().Select(n => PutHtmlElementsInXhtmlNamespace(n)));
}
return input;
}
In this way you can easily create data that's suitable for use in an RTF. Piecing the rest of a Content element together with XElement is pretty easy too, or of course, you can use the venerable Fields class for the rest.
Stripping namespace declarations from XML
I've recently been working on an application that will allow members of our content management teams to search within a chosen folder in Tridion for specific content. You might think that's well enough covered by the built-in search functionality, but we're heading towards a search and replace feature, so we pretty much have to process the content ourselves. In the end users' view of the world, a Rich Text field in a component has... well... a rich text view, and, for the power-users, a Source tab where you can see the underlying HTML. That's all fine, but once you get to the technical implementation, it's a bit more complicated, and we'll end up replicating some of Tridion's own smoke and mirrors to present a view to the users that's consistent with what they are used to. This means not only that we need to be able to translate from text to HTML, but also from "XML in the XHTML namespace" to HTML. One of the bulding blocks we need to do this is the ability to take XML with namespace declarations, and get rid of them so that the result isn't in a namespace.
A purist (such as myself) might say that the only correct way to parse XML is with an XML parser, and just in case you've never ended up there, I heartily recommend that you read this answer on Stack Exchange before proceding further. Still - in this case, what I want to do is amenable to RegExes, and yes, I know: now I have two problems. Anyway - FWIW - I started this at the office, thinking I'd just quickly Google for a namespace-stripping regex and I'd be on my way. Suffice it to say that the Internet is rubbish at this. I ended up with a page of links to rubbish regexes that just weren't going to float my boat. So I mailed the problem to myself at home, and today, in the quiet of a Sunday morning, it didn't seem quite so daunting. Actually, I'm still considering whether an XML-parser approach, or an XSLT might not be better, and I may end up there if my needs turn out to be more complex, but for now, here's the namespace stripper.
static Regex namespaceRegex = new Regex(@"
xmlns # literal (:[^\s=]+)? # : followed by one or more non-whitespace, non-equals chars \s* # optional whitespace = # literal \s* # optional whitespace (?<quote>['""]) # Either a single or double quote - giving it the name 'quote' for back-reference .+? # Non-greedily match anything \k<quote> # The end-quote to match the one we found earlier ", RegexOptions.Singleline | RegexOptions.IgnoreCase | RegexOptions.IgnorePatternWhitespace);
public static string RemoveNamespacesFromDocument(string xml) { return namespaceRegex.Replace(xml, string.Empty); }
Of course, this is written in C#, and I'm taking advantage of the IgnorePatternWhitespace feature in .NET regexes, which allows for the copious comments that might well be necessary if I ever have to actually read this code instead of just writing it.
But just in case you are hardcore, and all that named matches and commenting fuss is for wusses, here's the TL;DR...
@"(?is)xmlns(:[^\s=]+)?\s*=\s*(['""]).+?\2"
What's not to like? :-)
deployer-conf.xml barfs on the BOM
Today I was working on some scripts to provision, among other things, the SDL Web deployer service. It should have been straightforward enough, I thought. Just copy the relevant directory and fix up a couple of configuration files. Well I got that far, at least, but my deployer service wouldn't start. When I looked in the logs and found this:
2017-09-16 19:20:21,907 ERROR NonLegacyConfigConditional - The operation could not be performed.
com.sdl.delivery.configuration.ConfigurationException: Could not load legacy configuration
at com.sdl.delivery.deployer.configuration.DeployerConfigurationLoader.configure(DeployerConfigurationLoader.java:136)
at com.sdl.delivery.deployer.configuration.folder.NonLegacyConfigConditional.matches(NonLegacyConfigConditional.java:25)
I thought it was going to be a right head-scratcher. Fortunately, a little further down there was something a little more clue-bestowing:
Caused by: org.xml.sax.SAXParseException: Content is not allowed in prolog.
at org.apache.xerces.parsers.DOMParser.parse(Unknown Source)
at org.apache.xerces.jaxp.DocumentBuilderImpl.parse(Unknown Source)
at com.tridion.configuration.XMLConfigurationReader.readConfiguration(XMLConfigurationReader.java:124)
So it was about the XML. It seems that Xerxes thought I had content in my prolog. Great! At least, despite its protestations about a legacy configuration, there was a good clear message pointing to my "deployer-conf.xml". So I opened it up, thinking maybe my script had mangled something, but it all looked great. Then some subliminal, ancestral memory made me think of the Byte Order Mark. (OK, OK, it was Google, but honestly... the ancestors were there talking to me.)
I opened up the deployer-conf.xml again, this time in a byte editor, and there it was, as large as life:
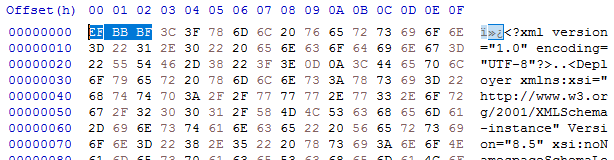
Three extra bytes that Xerxes thought had no business being there: the Byte Order Mark, or BOM. (I had to check that. I'm more used to a two-byte BOM, but for UTF-8 it's three. And yes - do follow this link for a more in-depth read, especially if you don't know what a BOM is for. All will be revealed.)
What you'll also find if you follow that link is that Xerxes is perfectly entitled to think that, as it's a "non-normative" part of the standard. Great eh?
Anyway - so how did the BOM get there, and what was the solution?
My provisioning scripts are written in Windows PowerShell, and I'd chosen to use PowerShell's "native" XML processing, which amounts to System.Xml.XmlDocument. In previous versions of these scripts, I'd used XLinq, but it's not really a good fit with PowerShell as you can't really use XPath without extension methods. So I gave up XLinq's ease of parsing fragments for a return to XmlDocument. To be honest, I wouldn't be surprised if the BOM problem also happens with XLinq: after all, it's Xerxes that's being fussy - you could argue Microsoft is playing "by the book".
So what I was doing was this.
$config = [xml](gc $deployerConfig)
Obviously, $deployerConfig refers to the configuration file, and I'm using Powershell's Get-Content cmdlet to read the file from disk. The [xml] cast automatically loads it into an XmlDocument, represented by the $config variable. I then do various manipulations in the XmlDocument, and eventually I want to write it back to disk. The obvious thing to do is just use the Save() method to write it back to the same location, like this:
$config.Save($deployerConfig)
Unfortunately, this gives us the unwanted BOM, so instead we have to explicitly control the encoding, like this:
$encoding = new-object System.Text.UTF8Encoding $false
$writer = new-object System.IO.StreamWriter($deployerConfig,$false,$encoding) $config.Save($writer) $writer.Close()
As you can see, we're still using Save(), but this time with the overload that writes to a stream, and also allows us to pass in an encoding. This seems to work fine, and Xerces doesn't cough it's lunch up when you try to start the deployer.
I think it will be increasingly common for people to script their setups. SDL's own "quickinstall" doesn't use an XML parser at all, but simply does string replacements based on its own, presumably hand-made, copies of the configuration files. Still - one of the obvious benefits of having XML configuration files is that you can use XML processing tools to manipulate them, so I hope future versions of the content delivery microservices will be more robust in this respect. Until then, here's the workaround. As usual - any feedback or alternative approaches are welcome.
Revisiting validateXml
Some time back in 2009 I blogged about validating Tridion's content delivery configuration files. It was a good idea then, and it's remained a good idea ever since. These days, we're dealing with SDL Web 8 and with the new micro-services architecture, you've got a lot of configuration files to get right. (On my fairly unambitious test system, running staging and live together, I just counted almost 80 configuration files.) Fortunately these seem to be reliably supported with schema files that are simply in each of the microservice folders that you copy during an installation.
Back when I first wrote the ValidateXmlFile powershell function, I'd left it rather unfinished. It was good enough to let me do some validations and detect problems, but it had a significant flaw, in that if a schema file was not present at the location indicated by the noNamespaceSchemaLocation attribute, it would simply not bother with validation. Considering that we're using an XmlReader to do the validation, this is a pretty reasonable design decision - after all the main purpose is to read in the XML, and validation is perhaps a bit of a side-effect. Fair enough, but it's a nasty hole in our defences, so now that I'm revisiting the technique, I've beefed up the script a bit so that it checks that the location is present and that there's a file in the location.
I've also made sure that the script does some pushd/popd to make sure that everything is nicely lined up when the location is relative to the file (which it generally is).
Here's the updated script:
function ValidateXmlFile {
param ([string]$xmlFile = $(read-host "Please specify the path to the Xml file"))
$xmlFile = resolve-path $xmlFile
"==============================================================="
"Validating $xmlFile using the schemas locations specified in it"
"==============================================================="
# The validating reader silently fails to catch any problems if the schema locations aren't set up properly
# So attempt to get to the right place....
pushd (Split-Path $xmlFile)
try {
$ns = @{xsi='http://www.w3.org/2001/XMLSchema-instance'}
# of course, if it's not well formed, it will barf here. Then we've also found a problem
# use * in the XPath because not all files begin with Configuration any more. We'll still
# assume the location is on the root element
$locationAttr = Select-Xml -Path $xmlFile -Namespace $ns -XPath */@xsi:noNamespaceSchemaLocation
if ($locationAttr -eq $null) {throw "Can't find schema location attribute. This ain't gonna work"}
$schemaLocation = resolve-path $locationAttr.Path
if ($schemaLocation -eq $null)
{
throw "Can't find schema at location specified in Xml file. Bailing"
}
$settings = new-object System.Xml.XmlReaderSettings
$settings.ValidationType = [System.Xml.ValidationType]::Schema
$settings.ValidationFlags = $settings.ValidationFlags `
-bor [System.Xml.Schema.XmlSchemaValidationFlags]::ProcessSchemaLocation
$handler = [System.Xml.Schema.ValidationEventHandler] {
$args = $_ # entering new block so copy $_
switch ($args.Severity) {
Error {
# Exception is an XmlSchemaException
Write-Host "ERROR: line $($args.Exception.LineNumber)" -nonewline
Write-Host " position $($args.Exception.LinePosition)"
Write-Host $args.Message
break
}
Warning {
# So far, everything that has caused the handler to fire, has caused an Error...
# So this /might/ be unreachable
Write-Host "Warning:: " + $args.Message
break
}
}
}
$settings.add_ValidationEventHandler($handler)
$reader = [System.Xml.XmlReader]::Create($xmlfile, $settings)
while($reader.Read()){}
$reader.Close()
}
catch {
throw
}
finally {
popd
}
}
Of course, what you really want is to be able to verify all your configurations in one go. Once the script is in your powershell $profile, you can put together some fairly simple command-line-fu to take care of that. I have all my microservices in one directory, which I guess is a pretty common pattern, so all I had to do was CD over there and execute the following:
gci -r -file -include *conf.xml | % {ValidateXmlFile $_}
By running this, I've also picked a couple of things that might be false positives. That aside, this is a real time saver if you're trying to solve issues. There's nothing like being able to eliminate a lot of the stupid typos from consideration all in one go.
Getting the complete component XML
One of the basic operations that a Tridion developer needs to be able to do is getting the full XML of a Component. Sometimes you only need the content, but say, for example that you're writing an XSLT that transforms the full Component document - you need to be able to get an accurate representation of the underlying storage format (OK - for now let's just skate over the fact that different versions have different XML formats under the water)
In the balmy days of early R5 versions, this was pretty easy to do. The Tridion installation included a "protocol handler", which meant that if you just pasted a TCM URI into the address bar of your browser, you'd get the XML of that item displayed in the browser. This functionality was actually present so that you could reference Tridion items via the document() function in an XSLT, but this was a pretty useful side effect. OK... you had to be on the server itself, but hey - that's not usually so hard for a developer. If you couldn't get on the server, or you found it less convenient, another option was to configure the GUI to be in debug mode, and you'd get an extra button that opened up some "secret" dialogs that gave you access to, among other things, the XML of the item you had open in the GUI.
Moving on a little to the present day, things are a bit different. Tridion versions since 2011 have a completely different GUI, and XSTL transforms are usually done via the .NET framework, which has other ways of supporting access to "arbitrary" URIs in your XSLT. The GUI itself is built on a framework of supported APIs, but doesn't have a secret "debug" setting. However, this isn't a problem, because all modern browsers come fully loaded with pretty powerful debugging tools.
So how do we go about getting the XML if we're running an up-to-date version of Tridion? This question cropped up just a couple of days ago on my current project, where there's an upgrade from Tridion 2009 to 2013 going on. I didn't really have a simple answer - so here's how the complicated answer goes:
My first option when "talking to Tridion" is usually the core service. The TOM.NET API will give you the XML of an item directly via the .ToXml() methods. Unfortunately, someone chose not to surface this in the core service API. Don't ask me why? Anyway - for this kind of development work, you could use the TOM.NET. You're not really supposed to use the TOM.NET for code that isn't hosted by Tridion (such as templates) but on your development server, what the eye doesn't see the heart won't grieve over. Of course, in production code, you should take SDL's advice on such things rather more seriously. But we're not reduced to that just yet.
Firstly, a brief stop along the way to explain how we solved the problem in the short term. Simply enough - we just fired up a powershell and used it to access the good-old-fashioned TOM.COM. Like this:
PS C:\> $tdse = new-object -com TDS.TDSE
PS C:\> $tdse.GetObject("tcm:2115-5977",1).GetXml(1919)
Simple enough, and it gets the job done... but did I mention? We have the legacy pack installed, and I don't suppose this would work unless you have.
So can it be done at all with the core service? Actually, it can, but you have to piece the various parts together yourself. I did this once, a long time ago, and if you're interested, you can check out my ComponentFactory class over on a long lost branch of the Tridion power tools project. But that's probably too much fuss for day to day work. Maybe there are interesting possibilities for a powershell module to make it easier, but again.... not today.
But thinking about these things triggered me to remember the Power tools project. One of the power tools integrates an extra tab into your item popup, giving you the raw XML view. I'd been thinking to myself that the GUI API (Anguilla) probably had reasonably easy support for what we're trying to do, but I didn't want to go to the effort of figuring it all out. Never fear: after a quick poke around in the sources I found a file called ItemXmlTab.ascx.js, and there I found the following gem:
var xmlSource = $display.getItem().getXml();
That's all you need. The thing is... the power tool is great. It does what it says on the box, and as far as I'm concerned, it's an exceedingly good idea to install it on your development server. But still, there are reasons why you might not. Your server might be managed by someone else, and they might not be so keen, or you might be doing some GUI extension development yourself and want to keep a clear field of view without other people's extensions cluttering up the system. Whatever - sometimes it won't be there, and you'd still like to be able to just suck that goodness out of Tridion.
Fortunately - it's not a problem. Remember when I said most modern browsers have good development tools? We use them all the time, right? F12 in pretty much any browser will get you there - then you need to be able to find the console. Some browsers will take you straight there with Ctrl+Shift+J. So you just open the relevant Tridion item, go to the console and grab the XML. Here's a screenshot from my dev image.

So now you can get the XML of an item on pretty much any modern Tridion system without installing a thing. Cool, eh? Now some of you at the back are throwing things and muttering something about shouldn't it be a bookmarklet? Yes it should. That's somewhere on my list, unless you beat me to it.
A poor man's Component synchroniser - or using the .NET framework to run XSLT from the PowerShell
Just lately, I've been doing some work on porting the old Component Synchroniser power tool to the current version of Tridion. If you are familiar with the original implementation, you might know that it is based on a pretty advanced XSLT transformation (thankfully, that's not the part that needs porting), that pulls in data about the fields specified by the schema (including recursive evaluation of embedded schemas), and ensures that the component data is valid in terms of the schema. Quite often on an upgrade or migration project, any schema changes can be dealt with well enough by this approach, but sometimes you need to write a custom transformation to get your old component data to match the changes you've made in your schema. For example, the generic component synchroniser will remove any data that no longer has a field, but if you add a new field that needs to be populated on the basis of one of the old fields, you'll be reaching for your favourite XSLT editor and knocking up a migration transform.
This might sound like a lot of work, but very often, it isn't that painful. In any case, the XSLT itself is the hard part. The rest is just about having some boilerplate code to execute the transform. In the past, I've used various approaches, including quick-and-dirty console apps written in C#. As you probably know, in recent times, I've been a big fan of using the Windows Powershell to work with Tridion servers, and when I had to fix up some component migrations last week, of course, I looked to see whether it could be done with the PowerShell. A quick Google led me (as often happens!) to Scott Hanselman's site where he describes a technique using NXSLT2. Sadly, NXSLT2 now seems to be defunct, and anyway it struck me as perhaps inelegant, or at the least less PowerShell-ish to have to install another executable, when I already have the .NET framework,, with System.Xml.Xsl.XslCompiledTransform, available to me.
I've looked at doing XSLT transforms this way before, but there are so many overloads (of everything) that sometimes you end up being seduced by memory streams and 19 flavours of readers and writers. This time, I remembered System.IO.StringWriter, and the resulting execution of the transform took about four lines of code. The rest of what you see below is Tridion code that executes the transform against all the components based on a given schema. Sharp-eyed observers will note that in spite of a recent post here to the effect that I'm trying to wean myself from the TOM to the core service, this is TOM code. Yup - I was working on a Tridion 2009 server, so that was my only option. The good news is that the same PowerShell/XSLT technique will work just as well with the core service.
$tdse = new-object -com TDS.TDSE
$xslt = new-object System.Xml.XmlDocument$xslt.Load("c:\Somewhere\TransformFooComponent.xslt")$transform = new-object System.Xml.Xsl.XslCompiledTransform$transform.Load($xslt)$sb = new-object System.Text.StringBuilder$writer = new-object System.IO.StringWriter $sbfilter FixFooComponent(){$sb.Length = 0$component = $tdse.GetObject($_, 2)$xml = [xml]$component.GetXml(1919)$transform.Transform($xml, $null, $writer)$component.UpdateXml($sb.ToString())$component.Save($true)}$schema = $tdse.GetObject("/webdav/SomePub/Building%20Blocks/System/Schemas/Foo.xsd",1)([xml]$schema.Info.GetListUsingItems()).ListUsingItems.Item | ? {$_.Type -eq 16}| %{$_.ID} | FixFooComponent
A thing of beauty is a joy for ever
So - I've been using the Windows Powershell for the odd bit of Tridion work. You knew that.
And you probably also knew that very often the Tridion API hands you back a string representing an XML document, and that it's very convenient to "cast" this to a .NET XmlDocument using the [xml] operator. Just search on this blog for "powershell" and you'll find enough examples. But still - there's a missing piece in the puzzle. So today I wanted to look at the output from the .GetTridionWebSchemaXMl() method on a Tridion Object Model Schema object. (Don't worry - I am weaning myself off the TOM; I wanted to compare this API with the ReadSchemaFields() method on the core service client API.)
Anyway - for what it's worth, here's what the raw string looks like:
> $tdse.GetObject("tcm:21-509-8",1).GetTridionWebSchemaXML(1919,$true)<tcm:TridionWebSchema ID="tcm:21-509-8" IsEditable="false" xmlns:tcm="http://www.tridion.com/ContentManager/5.0"><tcm:Context xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext"><tcm:Publication xlink:type="simple" xlink:title="Synchroniser tests" xlink:href="tcm:0-21-1" /><tcm:OrganizationalItem xlink:type="simple" xlink:title="TestSchemaOne" xlink:href="tcm:21-50-2" /></tcm:Context><tcm:Info xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext"><tcm:LocationInfo><tcm:WebDAVURL>/webdav/Synchroniser%20tests/Building%20Blocks/TestSchemaOne/TestSchemaCategories.xsd</tcm:WebDAVURL><tcm:Path>\Synchroniser tests\Building Blocks\TestSchemaOne</tcm:Path></tcm:LocationInfo><tcm:BluePrintInfo><tcm:OwningPublication xlink:type="simple" xlink:title="Synchroniser tests" xlink:href="tcm:0-21-1" /><tcm:IsShared>false</tcm:IsShared><tcm:IsLocalized>false</tcm:IsLocalized></tcm:BluePrintInfo><tcm:VersionInfo><tcm:Version>3</tcm:Version><tcm:Revision>0</tcm:Revision><tcm:CreationDate>2012-07-07T18:28:23</tcm:CreationDate><tcm:RevisionDate>2012-07-09T20:18:21</tcm:RevisionDate><tcm:Creator xlink:type="simple" xlink:title="TRIDIONDEV\Administrator" xlink:href="tcm:0-11-65552" /><tcm:Revisor xlink:type="simple" xlink:title="TRIDIONDEV\Administrator" xlink:href="tcm:0-11-65552" /><tcm:ItemLock Title="No lock" Type="0" /><tcm:IsNew>false</tcm:IsNew></tcm:VersionInfo><tcm:AllowedActions><tcm:Actions Allow="1173513" Deny="102" Managed="0" /></tcm:AllowedActions></tcm:Info><tcm:Data xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext"><tcm:Title>TestSchemaCategories</tcm:Title><tcm:Description>TestSchemaCategories</tcm:Description><tcm:Purpose>Component</tcm:Purpose><tcm:NamespaceURI>uuid:f14d60ed-0f7c-4d1f-a2e3-97d1dfeb1a1f</tcm:NamespaceURI><tcm:RootElementName>Content</tcm:RootElementName><tcm:Fields><tcm:KeywordField><tcm:Name>ColoursOne</tcm:Name><tcm:Description>ColoursOne</tcm:Description><tcm:MinOccurs>1</tcm:MinOccurs><tcm:MaxOccurs>unbounded</tcm:MaxOccurs><tcm:Category xlink:type="simple" xlink:title="Colours" xlink:href="tcm:21-59-512" /><tcm:Size>1</tcm:Size><tcm:List Type="tree" /><tcm:ExtensionXml xmlns="http://www.sdltridion.com/ContentManager/R6" /></tcm:KeywordField><tcm:SingleLineTextField><tcm:Name>Animals</tcm:Name><tcm:Description>Test field with locally declared list</tcm:Description><tcm:MinOccurs>1</tcm:MinOccurs><tcm:MaxOccurs>1</tcm:MaxOccurs><tcm:Size>1</tcm:Size><tcm:List Type="select"><tcm:Entry>Horse</tcm:Entry><tcm:Entry>Haddock</tcm:Entry><tcm:Entry>Weasel</tcm:Entry></tcm:List><tcm:ExtensionXml xmlns="http://www.sdltridion.com/ContentManager/R6" /></tcm:SingleLineTextField></tcm:Fields><tcm:MetadataFields /><tcm:AllowedMultimediaTypes /><tcm:ComponentProcess xlink:type="simple" xlink:title="" xlink:href="tcm:0-0-0" /></tcm:Data></tcm:TridionWebSchema>
Yeah - erm ... Okaayyyy. Great.
OK - so how about we do the cast?
> [xml]$tdse.GetObject("tcm:21-509-8",1).GetTridionWebSchemaXML(1919,$true)
TridionWebSchema
----------------
TridionWebSchema
Well - at least you can read it.. but seriously - also not super helpful if you just want to scan the XML with good-old-fashioned human eyeballs.
So what can we do? Well I got to the point where I actually typed the following into Google:
powershell pretty print xml
and the first hit was on Keith Hill's blog. Keith had written a nice little function that looks like this:
function XmlPrettyPrint([string]$xml) {
$tr = new-object System.IO.StringReader($xml)
$settings = new-object System.Xml.XmlReaderSettings
$settings.CloseInput = $true
$settings.IgnoreWhitespace = $true
$reader = [System.Xml.XmlReader]::Create($tr, $settings)
$sw = new-object System.IO.StringWriter
$settings = new-object System.Xml.XmlWriterSettings
$settings.CloseOutput = $true
$settings.Indent = $true
$writer = [System.Xml.XmlWriter]::Create($sw, $settings)
while (!$reader.EOF) {
$writer.WriteNode($reader, $false)
}
$writer.Flush()
$result = $sw.ToString()
$reader.Close()
$writer.Close()
$result
}
A minute later, this function was in my Powershell profile (and I slightly altered the name and added an alias) so now I can do the following:
> ppx ([xml]$tdse.GetObject("tcm:21-509-8",1).GetTridionWebSchemaXML(1919,$true)).OuterXml
<?xml version="1.0" encoding="utf-16"?>
<tcm:TridionWebSchema ID="tcm:21-509-8" IsEditable="false" xmlns:tcm="http://www.tridion.com/ContentManager/5.0">
<tcm:Context xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext">
<tcm:Publication xlink:type="simple" xlink:title="Synchroniser tests" xlink:href="tcm:0-21-1" />
<tcm:OrganizationalItem xlink:type="simple" xlink:title="TestSchemaOne" xlink:href="tcm:21-50-2" />
</tcm:Context>
<tcm:Info xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext">
<tcm:LocationInfo>
<tcm:WebDAVURL>/webdav/Synchroniser%20tests/Building%20Blocks/TestSchemaOne/TestSchemaCategories.xsd</tcm:WebDAVURL>
<tcm:Path>\Synchroniser tests\Building Blocks\TestSchemaOne</tcm:Path>
</tcm:LocationInfo>
<tcm:BluePrintInfo>
<tcm:OwningPublication xlink:type="simple" xlink:title="Synchroniser tests" xlink:href="tcm:0-21-1" />
<tcm:IsShared>false</tcm:IsShared>
<tcm:IsLocalized>false</tcm:IsLocalized>
</tcm:BluePrintInfo>
<tcm:VersionInfo>
<tcm:Version>3</tcm:Version>
<tcm:Revision>0</tcm:Revision>
<tcm:CreationDate>2012-07-07T18:28:23</tcm:CreationDate>
<tcm:RevisionDate>2012-07-09T20:18:21</tcm:RevisionDate>
<tcm:Creator xlink:type="simple" xlink:title="TRIDIONDEV\Administrator" xlink:href="tcm:0-11-65552" />
<tcm:Revisor xlink:type="simple" xlink:title="TRIDIONDEV\Administrator" xlink:href="tcm:0-11-65552" />
<tcm:ItemLock Title="No lock" Type="0" />
<tcm:IsNew>false</tcm:IsNew>
</tcm:VersionInfo>
<tcm:AllowedActions>
<tcm:Actions Allow="1173513" Deny="102" Managed="0" />
</tcm:AllowedActions>
</tcm:Info>
<tcm:Data xmlns:xlink="http://www.w3.org/1999/xlink" xmlns:i="http://www.w3.org/2001/XMLSchema-instance" xmlns:transform-ext="urn:tridion:transform-ext"> <tcm:Title>TestSchemaCategories</tcm:Title>
<tcm:Description>TestSchemaCategories</tcm:Description>
<tcm:Purpose>Component</tcm:Purpose>
<tcm:NamespaceURI>uuid:f14d60ed-0f7c-4d1f-a2e3-97d1dfeb1a1f</tcm:NamespaceURI>
<tcm:RootElementName>Content</tcm:RootElementName>
<tcm:Fields>
<tcm:KeywordField>
<tcm:Name>ColoursOne</tcm:Name>
<tcm:Description>ColoursOne</tcm:Description>
<tcm:MinOccurs>1</tcm:MinOccurs>
<tcm:MaxOccurs>unbounded</tcm:MaxOccurs>
<tcm:Category xlink:type="simple" xlink:title="Colours" xlink:href="tcm:21-59-512" />
<tcm:Size>1</tcm:Size>
<tcm:List Type="tree" />
<tcm:ExtensionXml xmlns="http://www.sdltridion.com/ContentManager/R6" />
</tcm:KeywordField>
<tcm:SingleLineTextField>
<tcm:Name>Animals</tcm:Name>
<tcm:Description>Test field with locally declared list</tcm:Description>
<tcm:MinOccurs>1</tcm:MinOccurs>
<tcm:MaxOccurs>1</tcm:MaxOccurs>
<tcm:Size>1</tcm:Size>
<tcm:List Type="select">
<tcm:Entry>Horse</tcm:Entry>
<tcm:Entry>Haddock</tcm:Entry>
<tcm:Entry>Weasel</tcm:Entry>
</tcm:List>
<tcm:ExtensionXml xmlns="http://www.sdltridion.com/ContentManager/R6" />
</tcm:SingleLineTextField>
</tcm:Fields>
<tcm:MetadataFields />
<tcm:AllowedMultimediaTypes />
<tcm:ComponentProcess xlink:type="simple" xlink:title="" xlink:href="tcm:0-0-0" />
</tcm:Data>
</tcm:TridionWebSchema>
So what's my point? Well I have a couple:
- The Internet is great (by which I mean, the people of the Internet are great.). I could have written that function myself in about half an hour. But in practice I might not have had the energy to do so at 10pm on a working Monday. Thanks to Keith's willingness to share, I had my solution inside a minute - working and tested. How cool is that?
- Somehow, this has just taken a little bit of the friction out of my working day, not to mention my so-called free time. I can now pull data straight out of a method that returns string, and get human-readable XML. This stuff makes a difference.
Thanks Keith - and all the other Keith's out there.
P.S. Maybe even nicely formatted XML will never be a thing of beauty, so apologies to Keats.
XML Namespaces aren't mandatory, and tools shouldn't assume that they are.
In his recent blog posting on XML Namespaces, James Clark questions the universal goodness of namespaces. Of course, there is plenty of goodness there, but he's right to question it. He says the following:
For XML, what is done is done. As far as I can tell, there is zero interest amongst major vendors in cleaning up or simplifying XML. I have only two small suggestions, one for XML language designers and one for XML tool vendors:
-
For XML language designers, think whether it is really necessary to use XML Namespaces. Don’t just mindlessly stick everything in a namespace because everybody else does. Using namespaces is not without cost. There is no inherent virtue in forcing users to stick xmlns=”…” on the document element.
-
For XML vendors, make sure your tool has good support for documents that don’t use namespaces. For example, don’t make the namespace URI be the only way to automatically find a schema for a document
It's the second point that interests me. During a recent Tridion project, there was a requirement to accept data from an external source as an XML document. I wanted to use a Tridion component to store this data, as this would give me the benefits of XML Schema validation, and controlled publishing. The document didn't have a namespace, although it had a schema. In order to get this to work with Tridion, I had to go to the provider of the document, and get them to add a namespace. Tridion wouldn't allow me to create a schema whose target namespace was empty. It seemed a shame that even when hand-editing the schema (so presumably asserting that I knew what I was about) the system wouldn't let me make this choice.
At the time, I just got the other party to make the change, and went back to more important things. Maybe there's some internal constraint in the way Tridion works that prevents them from supporting this, or maybe it's such an edge case that no-one was ever bothered by it. If the former, then I can't think what the problem would be; there's no reason to abuse the namespace to locate the schema. Tridion's quite happy enough to allow several schemas targetting the same namespace, so what's so special about the "no" namespace? In Tridion components, XML attributes (quite correctly) are in no namespace, but as long as the correct schema gets used for validation, so what?
I suspect it's more likely that this just comes under the "edge case" heading, in which case, perhaps they can improve it in a future release.
XML Schema validation from Powershell - and how to keep your Tridion content delivery system neat and tidy
I don't know exactly when it was that Tridion started shipping the XML Schema files for the content delivery configuration files. For what it's worth, I only really became aware of it within the last few months. In that short time, schema validation has saved my ass at least twice when configuring a Tridion Content Delivery system. What's not to like? Never mind "What's not to like?" - I'll go further. Now that the guys over at Tridion have gone to the trouble of including these files as release assets - it is positively rude of you not to validate your config files.
Being a well-mannered kind of guy, I figured that I'd like to validate my configuration files not just once, but repeatedly. All the time, in fact. Whenever I make a change. The trouble is that the typical server where you find these things isn't loaded down with tools like XML Spy. The last time I validated a config file, it involved copying the offending article over to a file share, and then emailing it to myself on another machine. Not good. Not easy. Not very repeatable.
But enter our new hero, Windows 2008 Server - these days the deployment platform of choice if you want to run Tridion Content Delivery on a Windows box. And fully loaded for bear. At least the kind of bears you can hunt using powershell. Now that I can just reach out with powershell and grab useful bits of the .NET framework, I don't have any excuse any more, or anywhere to hide, so this afternoon, I set to work hacking up something to validate my configuration files. Well - of course, it could be any XML file. Maybe other people will find it useful too.
So to start with - I thought - just do the simplest thing. I needed to associate the xml files with their relevant schemas, and of course, I could have simply done that in the script, but then what if people move things around etc., so I decided that I would put the schemas in a directory on the server, and use XMLSchema-instance attributes to identify which schema belongs with each file.
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:noNamespaceSchemaLocation="schema.xsd"
OK - so I'd have to edit each of the half-dozen or so configuration files, but that's a one-off job, so not much trouble. The .NET framework's XmlReader can detect this, and use it to locate the correct schema. (although if it isn't correctly specified, you won't see any validation errors even if the file is incorrect. I'll hope to fix that in a later version of my script.)
I created a function in powershell, like this:
# So far this silently fails to catch any problems if the schema locations aren't set up properly
# needs more work I suppose. Until then it can still deliver value if set up correctly
function ValidateXmlFile {
param ([string]$xmlFile = $(read-host "Please specify the path to the Xml file"))
"==============================================================="
"Validating $xmlFile using the schemas locations specified in it"
"==============================================================="
$settings = new-object System.Xml.XmlReaderSettings
$settings.ValidationType = [System.Xml.ValidationType]::Schema
$settings.ValidationFlags = $settings.ValidationFlags `
-bor [System.Xml.Schema.XmlSchemaValidationFlags]::ProcessSchemaLocation
$handler = [System.Xml.Schema.ValidationEventHandler] {
$args = $_ # entering new block so copy $_
switch ($args.Severity) {
Error {
# Exception is an XmlSchemaException
Write-Host "ERROR: line $($args.Exception.LineNumber)" -nonewline
Write-Host " position $($args.Exception.LinePosition)"
Write-Host $args.Message
break
}
Warning {
# So far, everything that has caused the handler to fire, has caused an Error...
Write-Host "Warning:: Check that the schema location references are joined up properly."
break
}
}
}
$settings.add_ValidationEventHandler($handler)
$reader = [System.Xml.XmlReader]::Create($xmlfile, $settings)
while($reader.Read()){}
$reader.Close()
}
With this function in place, all I have to do is have a list of lines like the following:
ValidateXmlFile "C:\Program Files\Tridion\config\cd_instances_conf.xml" ValidateXmlFile "C:\Program Files\Tridion\config\live\cd_broker_conf.xml"
If I've made typos or whatever, I'll pretty soon find them, and this can easily save hours. My favourite mistake is typing the attributes in lower case. Typically in these config files, attributes begin with a capital letter. Once you've made a mistake like that, trust me, no amount of staring at the code will make it obvious. You can stare straight at it and not see it.
So there you have it - as always - comments or improvements are always welcome, particularly if anyone knows how to get the warnings to show up!
XPath and the dreaded distinction between default namespace and no namespace.
XPath and the dreaded distinction between default namespace and no namespace.
I thought I was pretty much an old hand at XML by now, and that the standard gotchas wouldn't catch me any more. Not so! The standardest gotcha of 'em all jumped up out of the slime today like something undead and there I was, gotcha'd again.
I suppose I was led astray by putting too much trust in the notion that the methods surfaced in an API would always be relevant. Stupid really, but perhaps if you follow along with the story you'll forgive me. The API in question was that of the .NET framework; specifically the XmlNamespaceManager class.
Let's say you have some XML like this:
<?xml version='1.0'?> <a:one xmlns:a='aaa'> <two xmlns='bbb'/> </a:one>
If you have this in an XmlDocument and you want to XPath to the < two/> element, the first thing you'd usually do is create an XmlNamespaceManager and add the namespaces that you want to use in your XPath expression. This allows you to create a mapping between the namepace prefixes in your expression and the namespaces they represent. In the document itself, the same thing is achieved by the namespace declarations you can see in the sample above, but these don't exist in the XPath expression; it needs its own namespace context, or it won't be able to address anything that's in a namespace. But more of this just now...
So there I was today trying to demonstrate some techniques to a colleague, and I wrote some code something like this:
NameTable nt = new NameTable();
XmlNamespaceManager nm = new XmlNamespaceManager(nt);
nm.AddNamespace("a", "aaa");
nm.AddNamespace(String.Empty, "bbb");
if (null == doc.SelectSingleNode("a:one/two", nm))
Console.WriteLine ("Couldn't match default namespace");
else
Console.WriteLine ("Matched default namespace");
... and to my horror the match failed. After a few quick changes I had something like this:
nm.AddNamespace("b", "bbb");
if (null == doc.SelectSingleNode("a:one/b:two", nm))
Console.WriteLine("Couldn't match b: namespace");
else
Console.WriteLine("Matched b: namespace");
... and on this occasion the match succeeded.
What was going on? Could I possiibly be the first human to set foot on a previously undiscovered bug in the framework? Suffice it to say that my moment of glory will have to wait. A quick hunt around on Microsoft's web site showed that half a dozen other people had reported this as a bug, and that Microsoft's response was "Won't fix."
What was going on?
Five or so years ago Martin Gudgin and the other luminaries teaching Developmentor's "Guerilla XML" course, had gone to extraordinary lengths to teach me and my fellow victims the difference between a node that is in a namespace, and one that isn't. Sorry Martin, I failed you.
It turns out that in the XPath standard it says the following
A QName in the node test is expanded into an expanded-name using the namespace
declarations from the expression context. This is the same way
expansion is done for element type names in start and end-tags except
that the default namespace declared with xmlns is not used: if the QName does not have
a prefix, then the namespace URI is null (this is the same way attribute names are
expanded). It is an error if the QName has a prefix for which there is
no namespace declaration in the expression context.
So - in XPath, no prefix means not in any namespace at all, just like for attributes. Microsoft's implementation is correct. Otherwise, if you had XML like this:
<?xml version='1.0'?> <one> <two xmlns='bbb'> <c:three xmlns:c="po"/> </two> <one>
... you'd be unable to write an XPath from the root element down to <c:three/>.
Now for the part where you forgive me for my stupidity:
If you look at the documentation for XmlNamespaceManager, it states very clearly that you can use the empty string to set the Default namespace. (To be fair, the documentation for selectSingleNode has a note which attempts to clarify matters.)
If you look at the rest of the API of XmlNamespaceManager, the reason for the confusion becomes clear. XmlNamespaceManager also supports methods like PushScope, GetNamespacesInScope, etc. which plainly aren't intended for use with XPath at all. It looks rather as though you could use an XmlNamespaceManager for managing your namespaces as you navigate through an XmlDocument, perhaps with a streaming library. In that context, setting the default namespace makes perfect sense. If you're using it with XPath though, it's completely irrelevant.
So repeat after me: A default namespace isn't the same thing as the empty namespace (aka null namespace, no namespace, not in a namespace, etc.)